
Research Guide—Getting Access
Academic publishing is a treat! With the average article costing upwards of $30 for a 24-hr PDF rental, getting access to vital research is becoming increasingly difficult. Below are some ways that people have managed to obtain access to articles and books for free.

Introduction
Academic publishing is a treat! With the average article costing upwards of $30 for a 24-hr PDF rental, getting access to vital research is becoming increasingly difficult. Below are some ways that people have managed to obtain access to articles and books for free. If you explore any of these, please do so at their own risk—they operate in a legal gray area.
Flowchart
Start with RED!
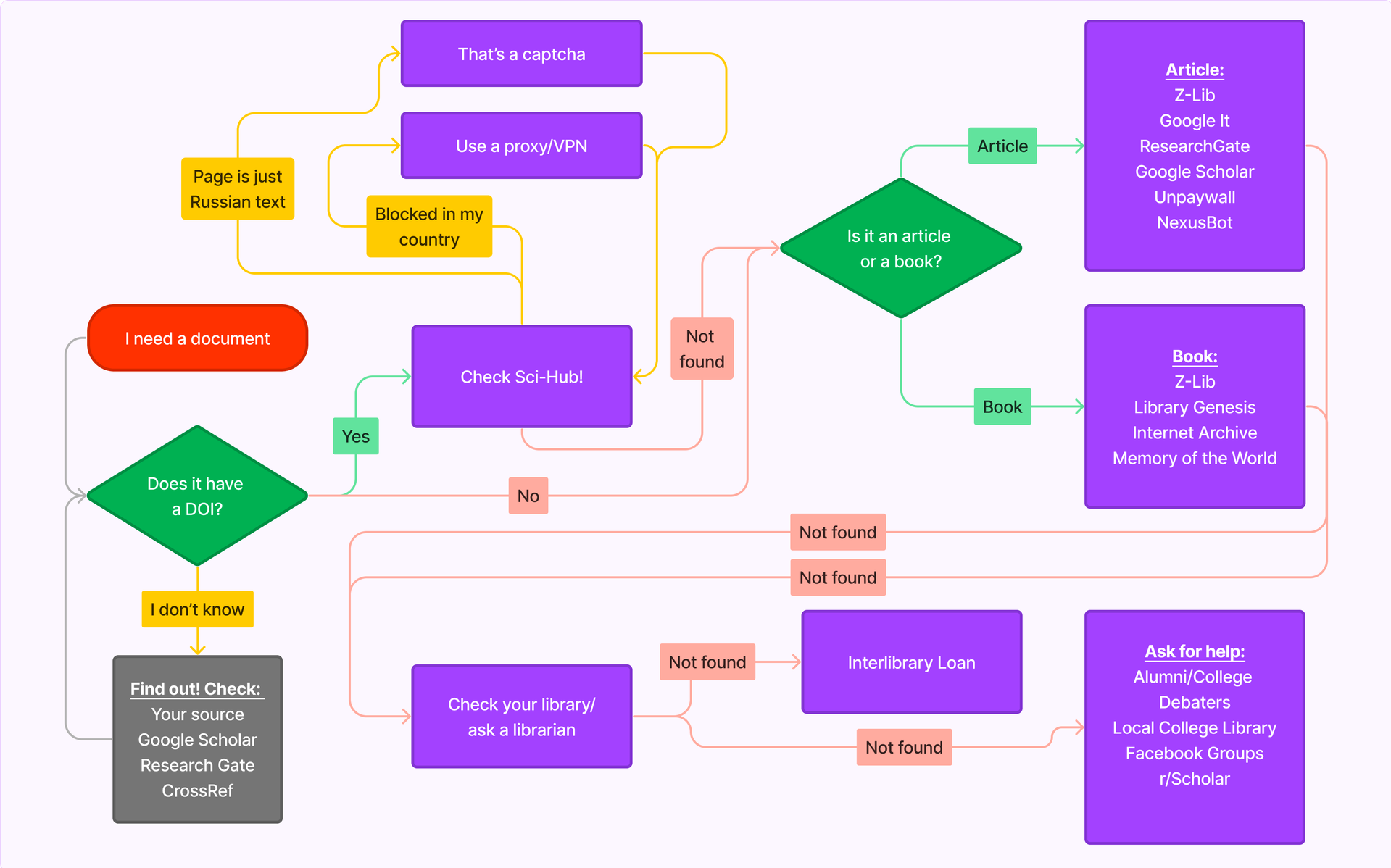
Getting Access—Start Here
Sci-Hub
Sci-Hub is an incredibly versatile and expansive tool. You can find it here. You can find Sci-Hub’s current proxies here.
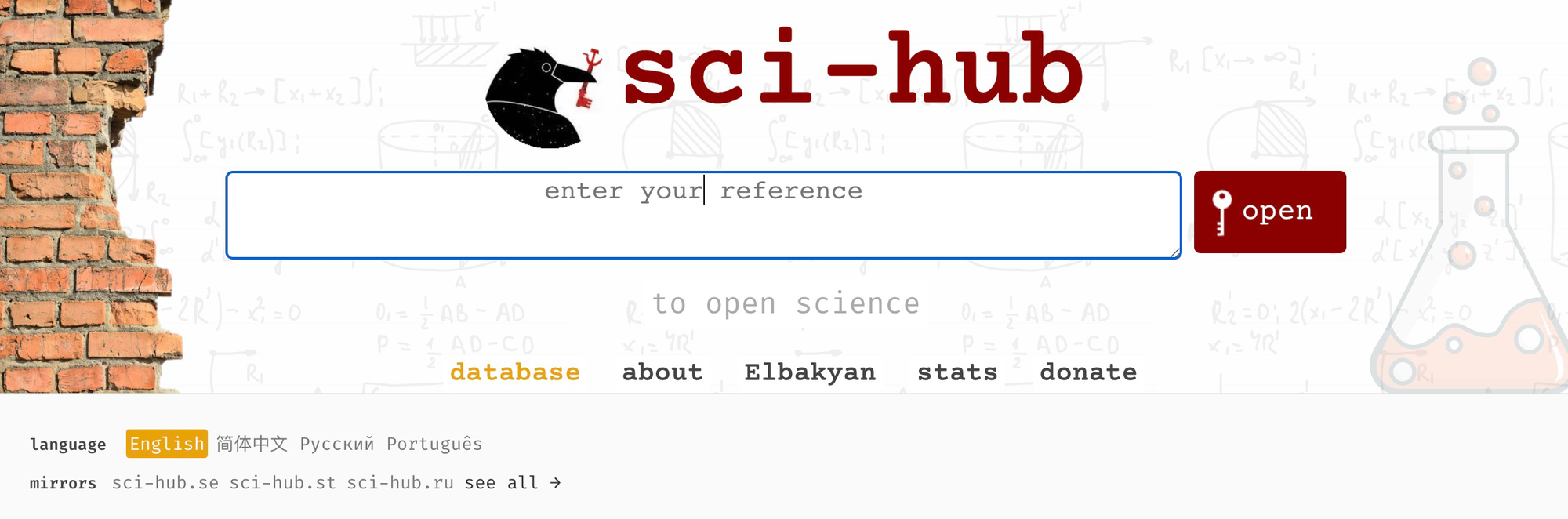
The best way to search it is with the DOI number. We can follow along with this article to see an example of how this works.
If you navigate to the webpage, you will see the following below the title:

Or, in the URL, you can see the following numbers: 10.1080/10736700.2018.1430552
If someone pops either of those things into Sci-Hub and if it has the PDF in its repository, it will immediately spit it out. Usually, inserting the entire URL will also do the trick, as Sci-Hub will automatically parse it for a DOI.
There may be a captcha to fill out.
To learn more about Sci-Hub—including how its coverage exceeded that of the University of Pennsylvania as of 2018—go here. Unfortunately, Sci-Hub’s post-2021 coverage is limited as a result of an Indian judicial proceeding. As The Print explains:
In December 2020, Sci-Hub had given an undertaking to the court that it would not upload any new papers on its website. On 6 January 2021, the court said that this undertaking would continue till the next hearing.
To read Cal State’s defense of its librarians’ descriptions of Sci-Hub in research classes, go here.
EDIT: MBA and Emory's Raleigh Maxwell pointed me to Anna's Archive, which appears to have picked up where Sci-Hub left off and provides a unified place to search with DOI and book title. Thank you Raleigh!
Library Genesis
You can think of Library Genesis—or LibGen—as Sci-Hub, but for books. You can find the basic version here, a slightly more advanced search interface with more options and the ability to search inside text here, and the desktop application here.
Unlike Sci-Hub, which can only be searched by DOI, LibGen can be searched by book title or (unreliably) by searching within the text of books. The best way to use LibGen is to find a book elsewhere and then plug the title into the search bar.
Z-Lib
Z-Lib, short for Z-Library, is a repository of books and academic articles spanning ~220TB. This is the most comprehensive single resource available, but is also difficult to access as a result of ongoing legal action.

The website is currently accessible by following the instructions here. You should create an account as soon as possible, as doing so unlocks a variety of additional access options that are more resilient. For example, I have been able to retain access despite other disruptions using Z-Library's desktop application.
Once you have an account, set up one or more of the following access options:
- Desktop Application. There are native versions for Windows, Mac, and Linux.
- Personal Domains: Your personal domain is a third-level clearnet (public internet) domain that you can use to access Z-Library without needing TOR. Using personal domains may provide a longer lifespan for accessing the library. You can find your personal domain from your account information. Bookmarking this domain ensures continued access to Z-Lib, even if public URLs are blocked.
- Android App. Download the
.apkhere. Read more about sideloading.apkfiles here. - Telegram Bot. Create your own telegram bot to request books from Telegram. You will be able to browse search results, select, and download any desired outputs.
NexusBot
NexusBot, hosted on STC (Standard Template Construct), is a self-replicating peer-to-peer search engine. It aims to make knowledge accessible without relying on a centralized server for hosting. NexusBot has a selection of books and articles that do not perfectly overlap with any other listed resource.
Unpaywall
Unpaywall is a Chrome addon that creates a little green button next to scholarly articles that have public full text somewhere else on the internet. Clicking this button when green will open a PDF.
Scholar Other Versions
Google Scholar search results give the option to view other versions of articles. Often this will include a link to a version of the article with a publicly accessible PDF.

Memory of the World
Memory of the World is a selective book repository that currently contains over 150,000 books with a focus on liberal arts and philosophy. This is worth checking if a philosophy or liberal arts text cannot be accessed via other means.
Other Long Shots
If all of the above options fail, there are a few long shot websites to attempt.
- ESSPC Ebooks—primarily fictional works. Access it here.
- Mobilism—quite wide-ranging, but difficult to browse. Access it here.
- Project Gutenberg—large repository of old, public domain works. Access it here.
Russian Language
The following resources allow you to access books and articles in Russian:
- CyberLeninka—Named after the colloquial name for the Russian State Library in Moscow, this website allows you to gain access to academic articles in Russian. You can read them online or download PDF copies.
- ELibrary—Provides access to an enormous range of Russian-language academic works, dissertations, and theses. You will likely need to use a VPN to access this service. I was able to access it through Estonia.
- Flibusta—Book repository containing primarily fictional works.
- GreyLib—Another Russian language book repository containing primarily fictional works.
Getting Access—Circumventing Paywalls
Sometimes, articles accessible on the internet are protected by paywalls that prevent you from reading the full text unless you have an account or have subscribed. Many of these paywalls can be circumvented.
Many of the techniques listed below are implemented automatically by the Bypass Paywalls Chrome Clean addon, which can also be configured to automatically disable Javascript or implement a different paywall circumvention technique for a particular site.
If this addon is breaking a particular site (commonly this will appear as the website reloading repeatedly or blocking you for being a robot) it can be disabled on a site-by-site basis.
Cookie-Based Paywalls
Many websites will allow you to view several articles for free without logging in but will cut off access after your first few articles. These websites keep track of how many pages you have viewed using ‘cookies’—small files stored user-side that identify the user to the website.
You can clear these files for a particular website and it will be unable to track you. There are a number of extensions that can do this, including this one called Cookie Remover.
Java-Based Paywalls
You can tell you are looking at a Java-based paywall when the text of an article appears momentarily and is then obscured by a blur effect or other element. This type of paywall stores the text on your computer, but covers it up with other web elements. You can remove these web elements using the console (accessible via F12). Failing that, after clicking around in the console you should be able to see all of the article text in the HTML for the page.
Additionally, certain means of access will provide the article without Java by default. These include:
- Google Cache. Google periodically saves copies of webpages. Sometimes this will let you sidestep soft paywalls. To try, enter ‘cache:’ before the URL.
- So, you would change—https://warontherocks.com/2021/01/why-overseas-military-bases-continue-to-make-sense-for-the-united-states/
- To—cache:https://warontherocks.com/2021/01/why-overseas-military-bases-continue-to-make-sense-for-the-united-states/ and press Enter.
- You can also search the article title and click on the cached version in the Google search results.
- WebArchive. Internet archive. Does the same thing as Google Cache, but isn’t Google, and saves multiple old versions of web pages so that you can theoretically see it change over time.
- Toggle Javascript. This chromium addon allows you to disable Javascript, which will frequently eliminate the paywall.
Several webpages access this version automatically:
Services that save a copy of the webpage can be used for this too:
- Pocket. Saves and organizes offline copies of articles for later reading.
- Archive.is. Saves archived copies of webpages in the cloud, similar to the Way Back Machine.
Note that these services will change the URL, so make sure you are putting the original URL in your card cites. When you use these methods, make sure to note the method of access and the date of the page snapshot. By definition, these services often access an out of date version of the webpage, which may have been updated since its last capture.
Account-Based Paywalls
In addition to the above tricks, the following approaches sometimes help:
- Make new accounts but add periods to your email. Gmail doesn’t care about periods so they will all go to your main email but many websites register those emails as being distinct accounts. This lets you make lots of free trials without making a bunch of different email accounts.
- Or register with a temporary email address, such as using Temp Mail.
Impenetrable Paywalls
Any paywall that sends the article and blocks access user-side can be circumvented. Many websites, however, have gotten wise, and no longer send the full text of the article to the user. Instead, they either send nothing or just the first few paragraphs. There is nothing you can do in these situations other than pay, use the library, or Google the article title in hopes that the full text has already been posted elsewhere.
Getting Access—Legal Briefs
PACER
PACER is the actual official way, but it costs $0.10/page and the process to make an account and activate the ability to search cases and download documents is really annoying. The link above is to the front end, but the actual portal where you search is district-specific and everything about this is user-unfriendly.
Court Listener
There's a free website that crawls PACER and you can get some of the documents for free, it lags PACER and seems like it used to give everything for free but then the government cracked down. Find it here.
PACER Monitor
There are piggyback websites such as PACER Monitor that crawl PACER and then sell you the documents for an upcharge and are slightly more user-friendly but otherwise have no value added over just using PACER.
My Source Isn’t Text—It’s…
…Some Weird File Format
Convert it!
- The best website to do this is Online Convert, which can be accessed here.
- The best offline application to do this is Calibre, a free app for ebook format conversion and management, which can be accessed here.
…A Locked PDF
Unlock it!
- SmallPDF—Unlock PDFs here.
…A Recording of Speech
Use an automatic transcription service!
- Default Apps—Many phones come with transcription notes apps, which you can use to transcribe audio by literally playing it out loud.
- Otter.ai—This service used to be a much better deal than it is now, but is still the most user-friendly transcription service. It contains a very convenient editor that syncs the audio to the text you are selecting, making its transcriptions very easy to edit.
…An Image
Use an Optical Character Recognition (OCR) tool!
- OnlineOCR—A free, mediocre, online application that performs this function can be found here.
- ABBYY FineReader—The gold standard is ABBYY, which you can find here.
- ShareX—This is a free, Windows-only tool that includes a rudimentary OCR. You can get it here.
…A Video
Download it, strip the audio, then use the audio tools above!
- If you are on MacOS, use Downie. Downie can extract and save videos from many webpages. Downie compliments Permute, which can convert between video and audio formats. It’s paid but comes with Setapp.
- Many websites will do something similar.
Conclusion
Your first resort should always be to access resources via your library or other institutional access methods. Nevertheless, I hope that this overview has provided some helpful insights into the ways people currently circumvent various paywalls and protections. Please explore this area with caution!